Blog
How to retrieve your Patreons automatically, using Java October 14, 2021
Patreon
By this point, most people know of the crowdfunding platform Patreon. To thank their supporters for their funding, most campains offer some sort of "Patreon recognition", my own included. Although a nice gesture that doesn't cost much, keeping track of your supporters manually can quickly become busywork. The solution is obvious: let's automate!
On that front, there is some good news and there is some bad news. The good news is that Patreon does offer a fairly extensive API. The bad news is that it is not actively supported at the moment and the support is relegated to the community. This means that while there is a way to automatically get your patreons using java, there is some updates to do to be able to do it on the most recent JDK.
Setup
In order to use the official Java client for the Patreon API, you will require two things: an access token and your campaign id. To get both, just follow these steps:
- Generate a Patreon Access Token, aka your API key
- Login to Patreon with your creator account
- Navigate to the "My Clients" configuration page
- Click the "Create client" button
- Fill-in the form. You only need to provide values for the required fields:
- App Name: The name of the application that will connect to Patreon
- Description: A short description of the application
- App Cateogry: Reason why the application connects to Patreon
- Redirect URIs: Whilst these will not be used as part of this tutorial, they would be the return URIs your users would get redirected to after authenticating
- Client API Version: must be set to
1
- Click the "Create Client" button
- Copy the value under "Creator's Access Token": this is your API key
- Get your campaign id
- Navigate to your campain's Patreon page, for example https://www.patreon.com/sc_trade_tools
- Open the developper's tools (usually done by pressing F12)
- In the javascript console tab, paste the following and hit Enter:
javascript:prompt('Campaign ID', window.patreon.bootstrap.creator.data.id); - The numerical value appearing in the pop-up is your campaign id
Client code
Example
build.gradle
...
dependencies {
...
implementation ('com.patreon:patreon:0.4.3') {
// custom built from https://github.com/EtienneLamoureux/patreon-java/tree/url-fix due to https://github.com/Patreon/patreon-java/issues/40
exclude group: 'org.slf4j', module: 'slf4j-log4j12'
}
...
}
...PatreonClient.java
import com.patreon.PatreonAPI;
import com.patreon.resources.Pledge;
import java.io.IOException;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
public class PatreonClient {
private PatreonAPI patreonApi;
private String campaign;
public PatreonClient(String campaign, String apiKey) {
this.patreonApi = new PatreonAPI(apiKey);
this.campaign = campaign;
}
public Collection<String> getPatreonNames() {
try {
List<Pledge> pledges = patreonApi.fetchAllPledges(campaign);
return pledges.parallelStream().filter(n -> n.getDeclinedSince() == null) // only paying Patreons
.filter(n -> n.getReward().getAmountCents() >= 300) // only $3.00+ tiers
.sorted((n, m) -> n.getCreatedAt().compareTo(m.getCreatedAt())) // sort by oldest first
.map(n -> n.getPatron().getFullName()).collect(Collectors.toList());
} catch (Exception e) {
return Collections.emptyList();
}
}
}Of course the above example code is provided as a starting point only. Depending on the framework you use, you could implement the following enhancements:
- Retry mechanism in case of error
- Cache the results for a few hours
- Do something different for different tiers of support
And that's it! Hopefully this has made automating the retrieval of your patreons easier that it was for me. Now we can only hope for the official API support to resume soon so community fixes like these are not required going forward.
Java Tutorial
Last updated on October 14, 2021
— Etienne Lamoureux
Local MariaDB Database, using Docker June 3, 2020
Installation
Run the following docker command:
docker run --name mariaDb -e MYSQL_ROOT_PASSWORD=root -d -p 3306:3306 -v mariaDbData:/var/lib/mysql mariadbWhere:
--namewill name the containermariaDb-pwill expose port3306to the host machine-vwill create a volume namedmariaDbData, so the database data will persist between uses
For more information, read docker run --help
Usage
The Docker container running the database can be used the same way as any other instance of a MySQL/MariaDB database. This means you can connect to it using PHPMyAdmin or any other database access tool, such as DBeaver.
MariaDB connection strings are formatted like so: jdbc:mariadb://<host>:<port>/<database>. The driver's class name is org.mariadb.jdbc.Driver. The table below contains the default connection information.
| Parameter | Value |
|---|---|
| Connection string | jdbc:mariadb://localhost:3306/<database> |
| Host | localhost |
| Port | 3306 |
| Database | You must create one |
| User | root |
| Password | root |
Maintenance
Connecting using mysql
To connect using mysql, simply run the following docker command:
> docker exec -ti mariaDb mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 14
Server version: 10.4.13-MariaDB-1:10.4.13+maria~bionic mariadb.org binary distribution
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>...
MariaDB [(none)]>exitWhere:
-tiallows to type in an interactive shell-uprovides the user using psql-pindicates that you wish to provide a password (enterrootwhen prompted)
For more information, read docker exec --help
Adding a new user and database
To add a new user and database, start by connecting to the container using mysql, then simply run the following commands:
MariaDB [(none)]>CREATE DATABASE <database>;
MariaDB [(none)]>GRANT ALL PRIVILEGES ON <database>.* TO '<user>'@'%' IDENTIFIED BY '<password>';Tailing the logs
To tail the logs, simply run the following docker command:
docker logs -f mariaDb --tail 500Where:
-fwill keep following the logs in real time--tailwill show the last 500 lines of log
For more information, read docker logs --help
Docker Cheatsheet
Last updated on June 3, 2020
— Etienne Lamoureux
Local Oracle Database, using Docker June 11, 2019
Installation
- Create a Docker account and login to the Docker Hub
- Install Docker (the instructions vary depending on your OS)
- Navigate to the Oracle Database Docker image on Docker Hub
- Click on "Proceed to checkout"
- Accept the licence
- Run the following docker commands:
> docker login
Authenticating with existing credentials...
Login Succeeded
> docker run -d -it --name oracleDb -p 1521:1521 -p 5500:5500 -v oracleDbData:/ORCL store/oracle/database-enterprise:12.2.0.1-slimWhere:
--namewill name the containeroracleDb-pwill expose both the1521and the5500ports to the host machine-vwill create a volume namedoracleDbData, so the database data will persist between uses
For more information, read docker run --help
Usage
The Docker container running the database can be used in the same way as any other instance of an Oracle database. This means you can connect to it using SQL*Plus or any other database access tool, such as DBeaver.
Oracle database connection strings are formatted like so: jdbc:oracle:thin:@<host>:<port>:<database>. The driver's class name is oracle.jdbc.driver.OracleDriver. The table below contains the default connection information.
| Parameter | Value |
|---|---|
| Connection string | jdbc:oracle:thin:@localhost:1521:ORCLCDB |
| Host | localhost or 10.0.75.1 (Windows) |
| Port | 1521 |
| Database | ORCLCDB |
| User | sys (might need to use sys AS SYSDBA) |
| Password | Oradoc_db1 |
| Role | SYSDBA or SYSOPER |
Maintenance
Connecting using sqlplus bash
To connect using sqlplus bash, simply run the following docker command:
docker exec -it oracleDb bash -c "source /home/oracle/.bashrc; sqlplus /nolog"Where:
-itallows to type in an interactive shell
For more information, read docker exec --help
To connect to the database itself, run the following commands:
SQL> connect SYS AS SYSDBA
Enter password: Oradoc_db1
Connected.
...
SQL> exitAdding a new user and database
To add a new user and database, start by connecting to the container using sqlplus bash, then simply run the following commands:
ALTER SESSION SET "_ORACLE_SCRIPT" = true;
CREATE USER <username> IDENTIFIED BY <password>;
GRANT RESOURCE TO <username>;
GRANT CONNECT TO <username>;
GRANT CREATE VIEW TO <username>;
GRANT CREATE SESSION TO <username>;
GRANT UNLIMITED TABLESPACE TO <username>;
GRANT SELECT ON SYS.DBA_RECYCLEBIN TO <username>;
exitFor more information, see this link
Tailing the logs
To tail the logs, simply run the following docker command:
docker logs -f oracleDb --tail 500Where:
-fwill keep following the logs in real time--tailwill show the last 500 lines of log
For more information, read docker logs --help
Docker Cheatsheet
Last updated on August 7, 2019
— Etienne Lamoureux
Local Postgres Database, using Docker April 18, 2019
Installation
Run the following docker command:
docker run --name postgresDb -e POSTGRES_PASSWORD=postgres -d -p 5432:5432 -v postgresDbData:/var/lib/postgresql/data postgresWhere:
--namewill name the containerpostgresDb-pwill expose port5432to the host machine-vwill create a volume namedpostgresDbData, so the database data will persist between uses
For more information, read docker run --help
Usage
The Docker container running the database can be used the same way as any other instance of a Postgres database. This means you can connect to it using PgAdmin or any other database access tool, such as DBeaver.
Postgres connection strings are formatted like so: jdbc:postgresql://<host>:<port>/<database>. The driver's class name is org.postgresql.Driver. The table below contains the default connection information.
| Parameter | Value |
|---|---|
| Connection string | jdbc:postgresql://localhost:5432/postgres |
| Host | localhost |
| Port | 5432 |
| Database | postgres |
| User | postgres |
| Password | postgres |
Maintenance
Connecting using psql
To connect using psql, simply run the following docker command:
> docker exec -ti postgresDb psql -U postgres
psql (11.2 (Debian 11.2-1.pgdg90+1))
Type "help" for help.
postgres=# ...
postgres=# exitWhere:
-tiallows to type in an interactive shell-Uprovides the user using psql
For more information, read docker exec --help
Adding a new user and database
To add a new user and database, start by connecting to the container using psql, then simply run the following commands:
postgres=# create user <user> with password '<password>';
postgres=# create database <database> owner <user>;
postgres=# exitTailing the logs
To tail the logs, simply run the following docker command:
docker logs -f postgresDb --tail 500Where:
-fwill keep following the logs in real time--tailwill show the last 500 lines of log
For more information, read docker logs --help
Docker Cheatsheet
Last updated on August 7, 2019
— Etienne Lamoureux
Handy Git script February 7, 2019
Preamble
If you're working with Git, especially with the command-line interface directly, you probably find yourself executing the same series of commands fairly frequently. Whether it's rebasing a current branch, starting a new one on top of the latest version of the code or cleaning-up a local repository, developers usually learn to view these mundane tasks as a necessary evil. I was no exception.
When working on projects, I usually work in my own fork, especially when other people are involved. Therefore, when I want to create a fresh new branch, I have to go through some git commands: git checkout master, git fetch --all, git rebase upstream/master, git push (I like to keep my fork up-to-date) and git checkout -b <new branch name>. Now, neither of these is particularly cumbersome. The whole process rarely even takes a minute. Still, it is very repetitive and a bit of a chore. One day, as I was waiting for an especially large change set to get fetched, I reflected on how ludicrous it was for me to still be doing this process "by hand". That's how I came to automate my way out of it:
Of course, as this is a fairly common problem, there are a number of similar scripts available online. Look around for the one that will make your life the easiest. Or maybe you have one of your own, or maybe you'll try your hand at it after reading this! Either way, it never hurts to look around for inspiration and seize the chance to learn something new in the process.
Usage
This is a .bat script, so Windows users only! After downloading it, place it in a folder that's listed in your global PATH variable to be able to use it everywhere. The script is best suited for people working in forks and using a different branch for everything. It also uses rebase instead of merge. Here's the full manual (also available in the script itself through the --help flag):
usage: git.bat <command> [<flags>]
# Commands
checkout stash, fetch --all, checkout <-mlb>, rebase <-r>/<-rb>, push, checkout -b <-b>
rebase stash, fetch --all, rebase <-r>/<-rb>
squash stash, fetch --all, reset --mixed <-r>/<-rb>, add -A, commit -m <-m>
cleanup gc --quiet, remote prune origin, branch -D <pruned remote branches>, git branch -a
# Flags
-mlb Main local branch, defaults to "master"
-b Local branch, usually to be created
-r Remote from which to update, defaults to "upstream"
-rb Branch on the remote from which to update, defaults to "master"
-mb Main branch, sets the value of both the "-mlb" and "-rb" flags
-m Commit message
# Examples
git.bat checkout -b new-local-branch
git.bat rebase
git.bat squash -m "squashed commit message"
git.bat cleanup
# License
CC BY-SA 4.0, Etienne Lamoureux
https://creativecommons.org/licenses/by-sa/4.0/Git
Last updated on September 19, 2019
— Etienne Lamoureux
How to use GitHub October 14, 2018
- Difficulty: Medium
- Time: 1 hour
- Prerequisite: Basic knowledge of Git
Table of contents
- 1. Install Git
- 2. Create a GitHub account
- 3. Setup your SSH key
- 4. Clone the project
- 5. Create a new branch
- 6. Commit often
- 7. Push
- 8. Create a pull request
So you want to use GitHub? Or maybe you have to, because it's your company's main repository. In any case, in this article I'll go in details on how to do just that, from the very beginning all the way to your first code contribution.
GitHub is not the only Git repository out there. The alternatives (BitBucket, GitLab, etc.) are also good options and you should compare the pros and cons of each before finalizing your choice. While this article will focus on GitHub, most of the steps apply to all Git repositories.
1. Install Git
First things first, if you want to use Git, you'll need it on your workstation. Head over to Git's download page and download the installer. Once the installer has finished downloading, simply run it and follow the instructions.
1.1 Windows
As Git is mainly a command-line tool, its installation can feel trickier on Windows. Luckily for Windows users, Git provides a neat installer to do all the work. Still, there are quite a few choices to make during the process and they came seems daunting at first. Let me walk you through the steps of the installer.
- Select components screen
- Recommended
- Git LFS (Large File Support)
- Associate
.gitconfiguration files with the default text editor - Associate
.shfiles to be run with the Bash
- Optional
- Windows Explorer integration: Useful if you don't like to navigate via the command line (using
cdcommands), this will add two options in the right-click menu of a folder to open the Git console and GUI.
- Windows Explorer integration: Useful if you don't like to navigate via the command line (using
- Recommended

- Choosing the default editor used by Git screen
- Notepad++: If you don't have it already, you can download it from their download page.
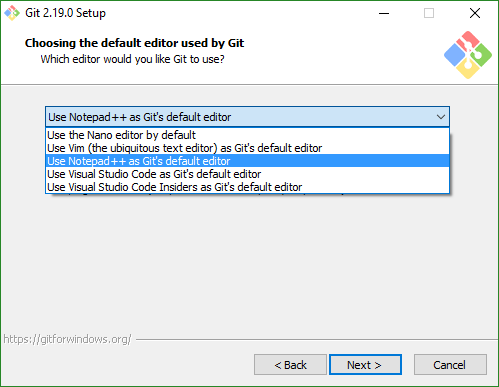
- Adjusting your PATH environment screen
- Use Git from Git Bash only: This is the recommended option and should be the one you choose. Consider the other options only if you really require them. If you're unsure, you don't require them.

- Choosing HTTPS transport backend screen
- Use the OpenSSL library: unless your organization requires you to use the Windows Secure Channel library, the default is recommended.
- Configuring the line ending conversions, screen
- Checkout Windows-style, commit Unix-style line endings: This is the option that will give you the least amount of trouble, so I recommend it. Unless you configure your code editor to properly manage Unix-style line endings, having Windows-style line endings will make your life easier. Whatever you do, do not choose Checkout as-is commit as-is, especially if you have team members working on Unix systems (lots of open source contributors use Unix systems).
- Configuring the terminal emulator to use with Git Bash screen
- Use MinTTY: The default works perfectly fine. Compared to Windows bash, it handles non-Unicode characters better and has colours (who doesn't like colours?).
- Configuring extra options screen
- Recommended
- Enable file system caching
- Enable Git Credential Manager
- Optional
- Enable symbolic links: If you're on Windows, chances are you're not using these very much. Not required.
- Recommended
2. Create a GitHub account
Now that you have Git installed on your local computer, it's time to create a GitHub account! Fill the sign-up form on their website. You may need to validate your email address to finish the registration process.
https://yourCompany.github.com/join. Ask your colleagues for the exact URL.2.1 Join an organization
Organizations are groups of users (people) along with the repositories (projects) they contribute to. They are a common and convenient way to manage permissions and roles in a consistent manner across multiple projects. For example, if you look at the CakePHP organization, you will see that a team of about 40 contributors works on upwards of 60 repositories. They use the organization as a way to white-list people that have write permission on the important branches of their projects, such as the main development branch, the current release branch, etc.
If you want to contribute to projects inside an organization, make sure to request access to their administrator. This may not apply to you for now, but it might sooner than you think!
3. Setup your SSH key
You're signed-up, your email address has been validated and you're ready to code! Well, almost. There are two ways to work with Git: using HTTPS and using SSH. HTTPS is very convenient in that is doesn't require any additional setup and you could start working right away. The downside is that in order to authenticate you, GitHub will ask you for your credentials (username and password) again and again and again... To avoid this, I therefore recommend using SSH. To do so, you will need to generate a special signature unique to your workstation, your SSH key, and give it to GitHub so it knows it's you. Git will then automatically provide this key to GitHub every time you would need to authenticate, all on its own.
Follow the steps of the GitHub's SSH key setup guide and come back here when you're all done.
4. Clone the project
Alright, ready? Let's copy the source code of the project on your workstation! Actually, we'll do more than that: we will copy the entire repository, which consists of the source code AND all of its previous revisions, on your workstation! This is because, as opposed to other versioning system such as SVN, Git is completely decentralized. Every copy of the repository IS the full repository, meaning that even if the "master" copy on GitHub disappears, nothing is lost. To clone a project, follow these steps:
- Navigate to the project you want to clone in GitHub
- Click the green "Clone or download" button
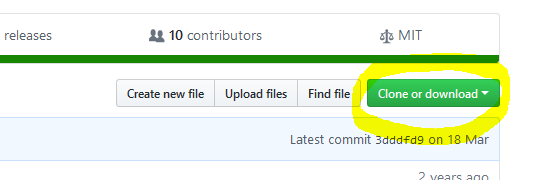
- Make sure the pop-up says "Clone with SSH". If it doesn't click the "Use SSH" link at the top-right of the pop-up

- Copy the string provided. It should start with
git@ - Open your Git command-line or terminal
- Using
cdcommands, navigate to where you want to project's folder to be cloned to- Example: if you want the project to be in
C:\workspace\java\<project>, navigate toC:\workspace\java
- Example: if you want the project to be in
- Type
git clonefollowed by the string you copied from GitHub and press Enter- If this is the first project you clone from GitHub, you will receive a warning about the fact that the authenticity of the host cannot be established. Verify that the host is in fact GitHub, and then press y, e, s, Enter
Git will then clone the repository to a folder with the same name as the project. The complete console log should look like this:
$ git clone git@github.com:<organization>/<project>.git
Cloning into '<project>'...
The authenticity of host 'github.com (192.30.253.113)' can't be established.
RSA key fingerprint is SHA256:<some long random-looking string>.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'github.com,192.30.253.113' (RSA) to the list of known hosts.
remote: Enumerating objects: 1, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 1366 (delta 0), reused 0 (delta 0), pack-reused 1365
Receiving objects: 100% (1366/1366), 18.71 MiB | 5.79 MiB/s, done.
Resolving deltas: 100% (975/975), done.
Checking connectivity... done.
$ cd <project>4.1 Fork the project
If you work on someone else's project, it is usually preferable to fork it before cloning it. Forking a project will simply copy the repository under your own namespace. It's a good idea to do so because it gives you your own copy of the project with which you can do as you please. It also has the benefit of restraining any screw-ups that might happen in your own copy, without any consequence to the main one.
To fork a project, simply navigate to the project's page on GitHub and click the "Fork" button (near the top-right), then select the namespace you want to fork it into (normally, your username's).

Once you've forked the project, you can clone it as detailed in step 4 above. Then, proceed to step 4.2: Add a remote.
4.2 Add a remote
A remote is a link between your local version of the repository and a fork that isn't your own. For example, if you forked the main repository into your own namespace and then cloned that fork, you should add the main repository as a remote to be able to stay up-to-date with the changes happening there. To add a remote to your local repository, run the following command:
$ git remote add --track <main branch on remote> <local name of remote> git@github.com:<organization>/<project>.gitWhere:
<main branch on remote>is the name of the branch you wish to track locally. Must exist in the parent repository.<local name of remote>is the name you are going to give to the parent repository on your workstation. It's entirely up to you. I like to useupstreamfor the main remote.git@github.com:<organization>/<project>.gitis the string you would use to clone the parent repository (from the green "Clone or download" button)
*For more information, see Git's documentation on remotes.
Example:
$ git remote add --track master upstream git@github.com:<organization>/<project>.git
$ git remote
origin
upstream5. Create a new branch
Working in a branch separate from the main one helps keeping things clean and organized. It also helps to easily be able to go back to a stable version of the code. When using feature-branches with Git, a new branch should be created for every single change you wish to make, no matter how small. To create a new branch, follow these steps:
- Make sure your local repository is up-to-date
- If you work directly on the main repository, simply run:
git fetch --allto get any new changes from the main repository you might not have locallygit checkout origin/masterto jump to the latest stable commit
- If you work in your own fork, run:
git fetch --allto get any new changes from the main repository you might not have locallygit checkout masterto go to your main local branchgit rebase upstream/masterto apply the changes from the main repository to your local one
- If you work directly on the main repository, simply run:
- Create a new branch using the
git checkout -b <new branch name>command - Code!
You may use a different branch than master as your main local branch and a different remote name than upstream for the main repository. If so, adapt the commands accordingly.
6. Commit often
Committing changes into Git is akin to pressing the "Save" button in a text editor: you should do it all the time. It's almost impossible to lose work once it's been committed into Git. So, since you don't want to lose work, commit often! Don't worry about messy commits: you can always amend the last commit to fix it later or even squash multiple commits together to tidy it up. Don't let that hinder you from committing often. To commit changes into Git, simply follow these instructions:
- Open your Git command-line or terminal
- Using
cdcommands, navigate to your project's folder - Run the
git guicommand - Click the "Rescan" button to allow the UI to pick-up your latest changes
- Stage the changes you want to commit from the top-left pane to the bottom-left pane by selecting them and pressing Ctrl+t
- You can Ctrl+click or Shift+click the files
- Write a clear and concise commit message on the first line, leaving the details to the next lines if required
- Press the "Commit" button
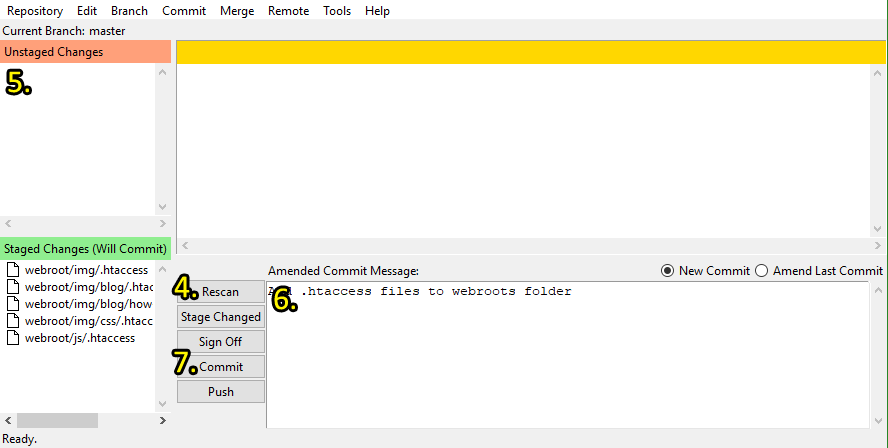
Keep the first line of the commit message short. The first line of the commit message should be clear, concise and to-the-point. You should think of it as the newspaper headline of the change set. The main reason for this is that most ways of viewing Git commits will only show the first line of the commit message and, even then, will cut it off after 80 characters or so. To keep it short, don't write about how you did the changes, but what you did, functionally. You can always go into more details in the following lines. If you don't know how to phrase your commit messages, simply write a short imperative statement as if ordering the commit itself to change the code, for example: "Change the maximum width of the username to 120 characters".
Don't commit formatting changes with functional changes. Going through a change log is hard enough as it is, going through one where mundane spacing changes are mixed up with functional code changes really isn't a pleasant experience. If you like the person that will have to look at your commits in the future, aka future-you, don't mix the two together!
Use the .gitignore file to avoid committing environment specific files or artifacts. Usually, environment specific files are not committed to the repository. This includes IDE project files, the Mac-specific .DS_Store file, etc. The reason for that is simple: not everyone might use the same environment you do! As for build artifacts, they are also usually excluded as everyone contributing to the project should compile their own. As such, they just take space in the repository.
6.1 Rebase often
If you work on a project as a member of a team, changes will constantly be merged into the main repository while you're working on yours. If you wait too long before syncing your local repository with the changes from the main repository, the code you're working on might end-up needing some serious adjustments or could even not be required anymore! To keep up with the changes, I recommend rebasing at least daily, depending on the size of your team and the frequency at which changes are merged into the main repository. To rebase, run:
git fetch --allgit rebase upstream/master- Fix the resulting conflicts, if any
Conflict resolution is a subject worthy of its own article. As such, I won't be discussing it here.
There is an alternative to rebasing: merging. I personally dislike it as it tends to make it more difficult to discern what happened when and before what. Multiple merges also tend to accumulate in long-lived branches, creating a rainbow of incoming branches that is even harder to decipher. Either way, rebase or merge, there is no way to avoid merge conflicts.
7. Push
Once your changes are ready, you can send them to GitHub using the push command. This will update the repository on GitHub with the changes that are currently only in your local repository. To push, simply run the git push command. If this is the first time you're pushing the branch, Git will let you know that you have to add some flags to the command. Copy the command given by Git and push your changes. The complete console log should look like this:
$ git push
fatal: The current branch <branch name> has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin <branch name>
$ git push --set-upstream origin <branch name>
Total 0 (delta 0), reused 0 (delta 0)
To git@github.com:<organization>/<project>.git
* [new branch] <branch name> -> <branch name>
Branch <branch name> set up to track remote branch <branch name> from origin.8. Create a pull request
You've done it: you've created a new change set in a branch! Ready to request to the repository administrator to take your contribution? Alright, first of all, head to GitHub and navigate your way to the main repository's page. Next, you will see a new yellow alert that wasn't there before. It will look like this:

If you forked the repository, you should still go to the main repository's page to create your pull request. GitHub will know you pushed your changes into a fork and will also know that you'll want them merged into the main repository. Therefore, the steps don't change, even if you forked!
Click the "Compare & pull request" button. This will bring you the pull request submission form. That form is divided into different parts:
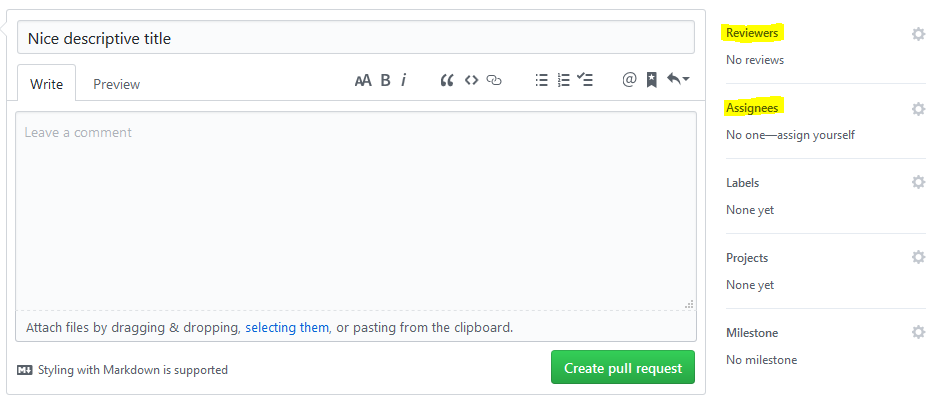
Let's take a look at them. At the top is the title of your pull request. Keep in mind the tips shared above about the first line of the commit message: the pull request title should respect those too. Once that's filled out, it's a good idea to describe what you did, at a high level, into the comment field. Add any important details you can think of and also any links to issues or tickets fixed or impacted by your pull request. Having cross-references make it much easier to go back and track the reason why certain changes happened.
Then there's the right sidebar. Its first section is to request reviews. I recommend all pull requests to be reviewed. By whom? Well that depends, but a good rule of thumb should be to assign pull requests to people that are intimately familiar with the area of the code you changed. They are the ones that will be able to make the most insightful comments about your changes. Those experts will also be able to tell you if you broke some fundamental assumption of the code that you might not have known about. In any case, always having at least one review never hurts. The second section is about the assignee. That person is the one that is responsible to formally accept your pull request into the repository. When you've filled everything, finish by clicking the green "Create pull request" button.
If you work on your own personal projects, there won't be a reviewer or an assignee. You may also want to skip on the pull request step altogether. However, knowing how it's done when multiple people are involved is never a bad idea, because sooner or later you might contribute to a larger project.
Depending on the repository, the branch in which change sets should be merged in may vary. You can choose which branch you want your pull request merged in when you create it. If you're unsure, ask the repository administrator.
There you go, you got through it all! Through this tutorial we've seen how to get the code base of a project from GitHub to your computer, how to stay up-to-date with the other contributors and finally, how to push your changes back to the master repository. Feel free to come back this page if need be: the commands never change and having a reference sheet is always handy. There is much more to learn about Git and GitHub but for now: go on and contribute!
Git Tutorial
Last updated on August 7, 2019
— Etienne Lamoureux
Dynamically change CakePHP language January 30, 2014
or how to control the locale of a CakePHP 2.x application by a parameter in the URL
Preamble
When I made the previous version of this website, I encountered a problem to which i found no satisfactory solution online: how to easily change the language of a CakePHP application. The framework's documentation itself doesn't help much, saying only:
There are several ways to do this, it can be by using language specific subdomains (en.example.com, fra.example.com, etc.), or using a prefix to the URL such as is done with this application. You may also wish to glean the information from the browser’s user-agent, among other things.
This is all well and good, but how to actually do it? And more importantly, how to do it in an elegant way, without polluting the entire application? Although Dorin Moise has managed to do something that works, the comments under his post suggest that a better solution is possible. In addition, the code managing the language change is mixed with AppController. When there is no satisfactory solution, the only thing left is to create one yourself! I invite you to check my complete solution on GitHub. The rest of this post will detail how to integrate the solution.
Installation Details
The heart of the module is located in the component LanguageComponent. To start, you must add the file in the Component folder in this location:
app/Controller/Component/LanguageComponent.php
Then, include the class in the application controller. In its definition, give the LanguageComponent the list of languages supported by your application. Note that the array key can be anything you choose. However, note that this is the value that will be used to recognize the language parameter in the URL. For the associated value, you must use an ISO 639-2 locale code. Here is an example:
app/Controller/AppController.php
public $components = array(
'Language' => array(
'supportedLanguages' => array(
'en' => 'eng',
'fr' => 'fra'
),
)
);Once the component included in the project, make sure that the links with language parameters are properly managed by the application. First, to ensure that the language is part of all the links in your application, you must redefine two functions:
app/Controller/AppController.php
public function redirect($url, $status = NULL, $exit = true)
{
if (is_array($url) && !isset($url['language']))
{
$url['language'] = $this->Language->getLanguage();
}
parent::redirect($url, $status, $exit);
}app/View/Helper/AppHelper.php
public function url($url = null, $full = false)
{
if(is_array($url) && !isset($url['language']))
{
$url['language'] = $_SESSION['Config']['languageCode'];
}
return parent::url($url, $full);
}Now that the user is always redirected to a page that contains the language in the URL, you must define this language parameter in your application's routes. This will require to modify the routes.php file like this:
app/Config/routes.php
//user-defined language codes here, must be same ones used for the LanguageComponent
$languageCodes = array('language' => 'en|fr');
Router::connect('/', array('controller' => 'pages', 'action' => 'display', 'home'));
Router::connect('/:language', array('controller' => 'pages', 'action' => 'display', 'home'), $languageCodes);
Router::connect('/:language/pages/*', array('controller' => 'pages', 'action' => 'display'), $languageCodes);
//default cakePHP routing, with language codes
Router::connect('/:language/:controller/:action/*', array(), $languageCodes);
Router::connect('/:language/:controller', array('action' => 'index'), $languageCodes);For safety, add a default locale for your application by defining it in core.php:
app/Config/core.php
/**
* Application default locale
* Must use an ISO 639-2 locale code
*/
Configure::write('Config.language', 'eng');For everything to work automatically, there are two more changes to do to the application controller. The first changes the locale of your application using this language parameter in the URL. The second gives you access to the current language of your application in all your views. Here they are:
app/Controller/AppController.php
public function beforeFilter()
{
$this->Language->set($this->params['language']);
}
function beforeRender()
{
$this->set('language', $this->Language->getLanguage()); //to access the language code from any view
}And voilà! The current language code is available in all your pages using the variable $language. To add a language-changing link to your pages, just add the language option in the options array $options = array() of a link created by HtmlHelper::link. For example:
echo $this->Html->link('Français', array('language'=>'fr'));CakePHP Internationalization PHP
Last updated on October 14, 2018
— Etienne Lamoureux